We’re excited to announce significant updates for Azure OpenAI Service, designed to help our 60,000 plus customers manage AI deployments more efficiently and cost-effectively beyond current pricing. With the introduction of self-service Provisioned deployments, we aim to help make your quota and deployment processes more agile, faster to market, and more economical. The technical value proposition remains unchanged—Provisioned deployments continue to be the best option for latency-sensitive and high-throughput applications. Today’s announcement includes self-service provisioning, visibility to service capacity and availability, and the introduction of Provisioned (PTU) hourly pricing and reservations to help with cost management and savings.
What’s new?
Self-Service Provisioning and Model Independent Quota Requests
We are introducing self-service provisioning alongside standard tokens, allowing you to request Provisioned Throughput Units (PTUs) more flexibly and efficiently. This new feature empowers you to manage your Azure OpenAI Service quata deployments independently without relying on support from your account team. By decoupling quota requests from specific models, you can now allocate resources based on your immediate needs and adjust as your requirements evolve. This change simplifies the process and accelerates your ability to deploy and scale your applications.
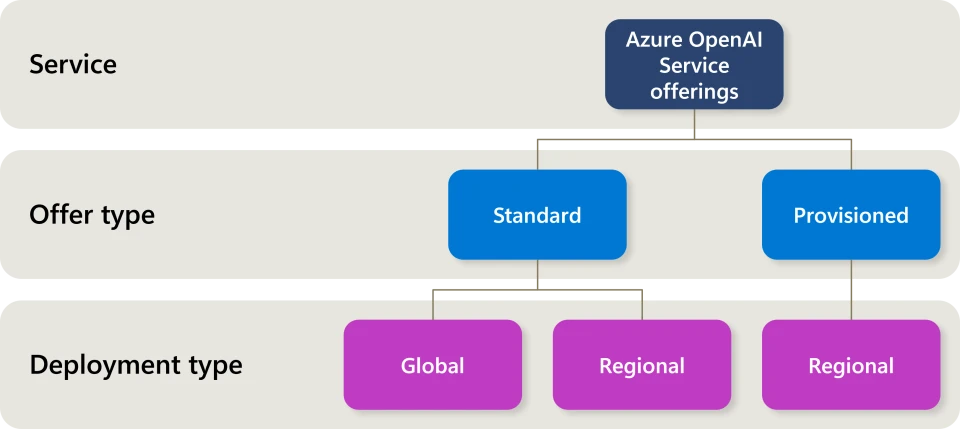
Visibility to service capacity and availability
Gain better visibility into service capacity and availability, helping you make informed decisions about your deployments. With this new feature, you can access real-time information about service capacity in different regions, ensuring that you can plan and manage your deployments more effectively. This transparency allows you to avoid potential capacity issues and optimize the distribution of your workloads across available resources, leading to improved performance and reliability for your applications.
Provisioned hourly pricing and reservations
We are excited to introduce two new self-service purchasing options for PTUs:
- Hourly no-commitment purchasing
- You can now create a Provisioned deployment for as little as an hour, with a flat hourly rate of $2 per unit per hour. This model-independent pricing makes it easy to deploy and tear down deployments as needed, offering maximum flexibility. This is ideal for testing scenarios or transitional periods without any long-term commitment.
- Monthly and yearly Azure reservations for Provisioned deployments
- For production environments with steady request volumes, Azure OpenAI Service Provisioned Reservations offer significant cost savings. By committing to a monthly or yearly reservation, you can save up to 82% or 85%, respectively, over hourly rates. Reservations are now decoupled from specific models and deployments, providing unmatched flexibility. This approach allows enterprises to optimize costs while maintaining the ability to switch models and adjust deployments as needed. Read our technical blog on Reservations here.
Benefits for decision makers
These updates are designed to provide flexibility, cost efficiency, and ease of use, making it simpler for decision-makers to manage AI deployments.
- Flexibility: With self-service provisioning and hourly pricing, you can scale your deployments up or down based on immediate needs without long-term commitments.
- Cost efficiency: Azure Reservations offer substantial savings for long-term use, enabling better budget planning and cost management.
- Ease of use: Enhanced visibility and simplified provisioning processes reduce administrative burdens, allowing your team to focus on strategic initiatives rather than operational details.
Customer success stories
Before we made self-service available, select customers started achieving benefits of these options.
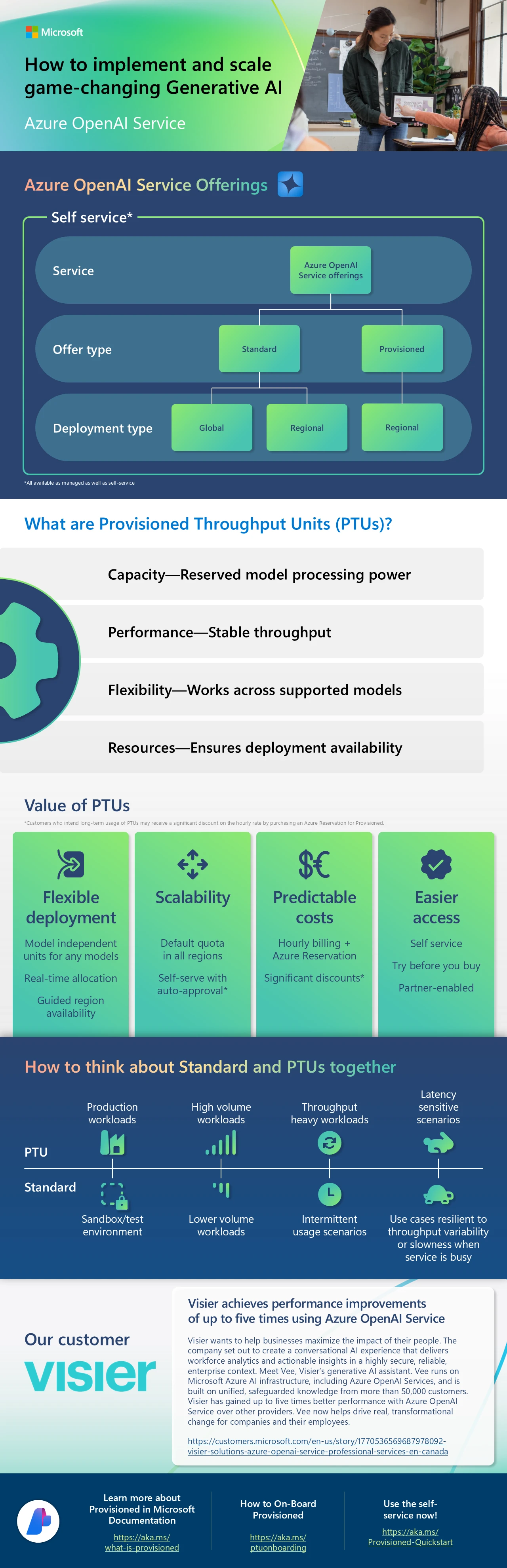
- Visier Solutions: By leveraging Provisioned Throughput Units (PTUs) with Azure OpenAI Service, Visier Solutions has significantly enhanced their AI-powered people analytics tool, Vee. With PTUs, Visier guarantees rapid, consistent response times, crucial for handling the high volume of queries from their extensive customer base. This powerful synergy between Visier’s innovative solutions and Azure’s robust infrastructure not only boosts customer satisfaction by delivering swift and accurate insights but also underscores Visier’s commitment to using cutting-edge technology to drive transformational change in workforce analytics. Read the case study on Microsoft.
- An analytics and insights company: Switched from Standard Deployments to GPT-4 Turbo PTUs and experienced a significant reduction in response times, from 10–20 seconds to just 2–3 seconds.
- A Chatbot Services company: Reported improved stability and lower latency with Azure PTUs, enhancing the performance of their services.
- A visual entertainment company: Noted a drastic latency improvement, from 12–13 seconds down to 2–3 seconds, enhancing user engagement.
Empowering all customers to build with Azure OpenAI Service
These new updates do not alter the technical excellence of Provisioned deployments, which continue to deliver low and predictable latency. Instead, they introduce a more flexible and cost-effective procurement model, making Azure OpenAI Service more accessible than ever. With self-service Provisioned, model-independent units, and both hourly and reserved pricing options, the barriers to entry have been drastically lowered.
To learn more about enhancing the reliability, security, and performance of your cloud and AI investments, explore the additional resources below.
Additional Resources
The post Elevate your AI deployments more efficiently with new deployment and cost management solutions for Azure OpenAI Service including self-service Provisioned appeared first on Azure Blog.